The Hitchhiker`s Guide to Binary-to-Text Encoding

Table of Contents
Either for debugging, data serialization, cryptography or ID generation, binary-to-text encoding is an important tool for most developers representing binary data in a sequence of printable characters. Either you currently want to select a specific one or just want to generally understand the basic properties of each, this article will provide you an overview.
One thing all of these encodings have in common, is that they require more space than the underlying bit-data. How much depends on the encoding and the size of its alphabet. Another important property is “human-readability”, so if you want to understand the underlying value at a glance, it will be way easier with a hex encoding than base64. Also don’t forget padding, required if a single character does not exactly represent 2, 4 or 8 bits, which makes the output length variable. Finally, you need to consider how readily available implementations of the chosen encoding is, especially if you want to send the data to different system using different tech stacks.
Encodings #
Binary #
Binary, also known as base-2 encoding, is the simplest and most fundamental binary-to-text encoding. It represents data using only two symbols: 0 and 1. In binary encoding, each byte (consisting of 8 bits) is directly translated into a sequence of eight 0s and 1s.
Binary encoding is best suited for situations where readability is not a primary concern, such as number encoding and debugging purposes. Although it is not widely used for general text encoding due to its verbosity, binary remains an essential building block in understanding more complex binary-to-text encoding schemes.
| Property | Value |
|---|---|
| Efficiency | 12.5 % (1 bit/char), 1 bit segments |
| 32/64/128 bit | 1-32/1-64/1-128 chars |
| Padding | false |
| Const. Out. Len. | false |
| Suited for | number encoding, debugging |
| Alphabet | 01 |
| Known Usages | none |
| Standardization | none |
| Popularity | implementations: common, usage: not common |
| Example | 11010011 01111000 01101100 10010011 01111110 01111111 00111000 |
Octal #
Octal, or base-8 encoding, represents data using eight distinct symbols: 0 through 7. In octal encoding, each byte (8 bits) is divided into three groups of 3 bits each, and each group is then converted into a single octal digit.
Octal encoding is particularly well-suited for number encoding applications, such as the Unix chmod command, which uses octal notation to represent file permissions. While not as prevalent as some others, octal remains a useful and compact representation for certain use cases, especially in contexts where base-8 arithmetic is more convenient or intuitive.
| Property | Value |
|---|---|
| Efficiency | 37.5 % (3 bit/char), 24 bit segments |
| 32/64/128 bit | 1-11/1-22/1-43 chars |
| Padding | false |
| Const. Out. Len. | false |
| Suited for | number encoding |
| Alphabet | 01234567 |
| Known Usages | chmod |
| Popularity | implementations: common, usage: not common |
| Standardization | none |
| Example | 703767722333074323 |
Decimal #
Decimal, or base-10 encoding, represents data using 0 through 9. In decimal encoding, bytes are treated as integer values and then converted to their corresponding decimal representation.
Decimal encoding is particularly suited for number encoding and single-byte representation applications. Due to its familiarity and ease of understanding, decimal encoding is often employed in contexts where readability is important, and the data being represented consists primarily of numerical values.
| Property | Value |
|---|---|
| Efficiency | 41.5 % (3.32 bit/char) |
| 32/64/128 bit | 1-10/1-20/1-39 chars |
| Padding | false |
| Const. Out. Len. | false |
| Suited for | number encoding |
| Alphabet | 0123456789 |
| Known Usages | single byte representations |
| Popularity | implementations: common, usage: not common |
| Standardization | none |
| Example | 15902780311763155 |
Hex #
Hexadecimal, often abbreviated as “hex” or referred to as base-16 encoding, is a widely used binary-to-text encoding method that represents data using sixteen distinct symbols: 0-9 and A-F (or a-f) for the digits 10 through 15. In hex encoding, each byte (8 bits) is divided into two groups of 4 bits each, with each group being converted into a single hex digit.
Hexadecimal encoding is particularly suited for number and byte-string encoding applications. It is widely used in various contexts, such as UUIDs, cryptographic keys, and color codes in web design, among others. Hex encoding has been standardized by RFC 4648, which provides guidelines on how this encoding method should be used and implemented in various applications.
| Property | Value |
|---|---|
| Efficiency | 50 % (4 bit/char), 8 bit segments |
| 32/64/128 bit | 8/16/32 chars |
| Padding | false |
| Const. Out. Len. | true |
| Suited for | number & byte-string encoding |
| Alphabet | 0123456789abcdef |
| Known Usages | UUIDs, color codes, cryptographic keys, … |
| Popularity | implementations: very common, usage: very common |
| Standardization | RFC 4648 |
| Example | 387f7e936c78d3 |
Base26 #
Base26 encoding, also known as alphabetic encoding, represents data using the 26 letters of the English alphabet (A-Z).
It is particularly suited for number encoding applications and may be useful in scenarios where the encoding output should only contain alphabetic characters. However, it is not widely adopted, and there are no known standardization or specific use cases for this encoding method.
| Property | Value |
|---|---|
| Efficiency | 58.8 % (4.70 bit/char) |
| 32/64/128 bit | 7/14/28 chars |
| Padding | false |
| Const. Out. Len. | true |
| Suited for | byte-string encoding |
| Alphabet | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| Known Usages | none |
| Popularity | implementations: not common, usage: not common |
| Standardization | none |
| Example | EIQYWQEAJRFF |
Base32 #
Base32 represents data using a set of 32 distinct characters, typically consisting of uppercase letters A-Z and digits 2-7. This encoding scheme is designed to be more human-readable and resistant to errors when compared to other schemes like base64, while still offering a relatively compact representation of data.
This encoding method is particularly well-suited for scenarios where data needs to be case-insensitive, easy to read, or less prone to transcription errors. Base32 has been standardized by RFC 4648 but has several variations.
| Property | Value |
|---|---|
| Efficiency | 62.5 % (5 bit/char), 40 bit segments |
| 32/64/128 bit | 7+1/13+3/26+6 chars (+padding) |
| Padding | true |
| Const. Out. Len. | true |
| Suited for | byte-string encoding |
| Alphabet | ABCDEFGHIJKLMNOPQRSTUVWXYZ234567 |
| Known Usages | none |
| Popularity | implementations: common, usage: not common |
| Standardization | RFC 4648 |
| Variations | z-base-32, Crockford’s Base32, base32hex, Geohash |
| Example | HB7X5E3MPDJQ |
Base36 #
Base36 represents data using a set of 36 distinct characters, consisting of both the 26 lowercase letters of the English alphabet (a-z) and the 10 Arabic numerals (0-9). This encoding scheme aims to provide a more compact and human-readable representation of data while still offering a balance between efficiency and readability.
Base36 encoding is particularly suited for applications that involve encoding large integers, such as unique identifiers or URL slugs.
| Property | Value |
|---|---|
| Efficiency | 64.6 % (5.17 bit/char) |
| 32/64/128 bit | 1-7/1-13/1-25 chars |
| Padding | false |
| Const. Out. Len. | false |
| Suited for | big integer encoding |
| Alphabet | 0123456789abcdefghijklmnopqrstuvwxyz |
| Known Usages | Reddit Url Slugs |
| Popularity | implementations: common, usage: somewhat common |
| Standardization | none |
| Example | 4cl2cf404wj |
Base58 #
Base58 encoding represents data using a set of 58 distinct characters, consisting of uppercase letters A-Z, lowercase letters a-z, and the digits 1-9, excluding visually similar characters such as ‘0’, ‘O’, ‘I’, and ’l’. This encoding scheme aims to provide a compact and human-readable representation of data while minimizing the risk of transcription errors.
While base58 encoding is not standardized, it has gained popularity in the cryptocurrency and distributed systems communities.
| Property | Value |
|---|---|
| Efficiency | 73.2 % (5.86 bit/char) |
| 32/64/128 bit | 6/11/22 chars |
| Padding | false |
| Const. Out. Len. | false |
| Suited for | big integer encoding |
| Alphabet | 123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz |
| Known Usages | Bitcoin, IFPS |
| Popularity | implementations: not common, usage: not common |
| Standardization | none |
| Variations | flicker short-urls |
| Example | 39BQ5CdzFL |
Base64 #
Base64 encoding is one of the most widely used binary-to-text encoding. It utilizes a set of 64 distinct characters, which includes uppercase letters A-Z, lowercase letters a-z, digits 0-9, and two additional characters, typically ‘+’ and ‘/’ (or ‘-’ and ‘_’ for the URL-safe variant). Padding is represented as ‘=’. This encoding scheme aims to provide a compact and universally compatible representation of data, allowing it to be safely transmitted or embedded in various environments.
Base64 encoding is particularly suited for applications that involve encoding byte strings, such as embedding images in HTML or transmitting binary data over text-based protocols like email. It is standardized in RFC 4648, with various variations defined in other RFCs, making it a widely recognized and supported encoding method across different platforms and programming languages.
| Property | Value |
|---|---|
| Efficiency | 75 % (6 bit/char), 24 bit segments |
| 32/64/128 bit | 6+2/11+1/22+2 chars (+padding) |
| Padding | true |
| Const. Out. Len. | true |
| Suited for | byte-string encoding |
| Alphabet | ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ |
| (url-safe) | ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_ |
| Known Usages | practically everywhere |
| Popularity | implementations: very common, usage: very common |
| Standardization | RFC 4648 (previously RFC 3548) |
| Variations | RFC 4880 (ASCII Armor), RFC 1421, RFC 2152, RFC 3501, bcrypt radix64 |
| Example | OH9-k2x40w |
OH9+k2x40w (url-safe) |
Ascii85 #
Ascii85, also known as Base85 encoding, uses a set of 85 distinct characters, which include all printable ASCII characters (except for whitespace) and an additional four characters that are used for padding and delimiting.
Ascii85 encoding is often used in environments where binary data needs to be represented in the most compact way.
| Property | Value |
|---|---|
| Efficiency | 80.1 % (6.41 bit/char) |
| 32/64/128 bit | 1-5/2-10/4-20 chars |
| Padding | false |
| Const. Out. Len. | false |
| Suited for | byte-string encoding |
| Alphabet | 123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz |
| Known Usages | Git, IPv6, Adobe PDF and PostScript |
| Popularity | implementations: not common, usage: somewhat common |
| Variations | 32/Z85 ZeroMQ, ZMODEM Pack-7 encoding, btoa, Adobe, RFC 1924 |
| Example | 3.HC@Cj=D |
Base122 #
Base122 is an experimental encoding that facilitates printable and non-printable characters to maximize space efficiency. Base-122 can be used in any context of binary-to-text embedding where the text encoding is UTF-8. There is a JavaScript and C reference implementation by the original author, with some options in Python, Java and Rust.
| Property | Value |
|---|---|
| Efficiency | 86.6 % (6.93 bit/char) |
| 32/64/128 bit | ? |
| Padding | false |
| Const. Out. Len. | false |
| Suited for | embedding blobs in HTML (experimental) |
| Alphabet | full 7bit minus some reserved chars (UTF-8 compatible) |
| Known Usages | none |
| Popularity | implementations: not common, usage: not common |
| Example | ��v�~� (non-printable characters, might not render correctly) |
Encoding while Compressed #
More Bits per char is always smaller, right? While sometimes the encoded character sequence is directly used, often, specifically when sending data through HTTP, it will be sent compressed rather than just encoded. Since compression algorithms might not be as intuitive as one thinks, I tested the different encodings with different data types to see how they behave:
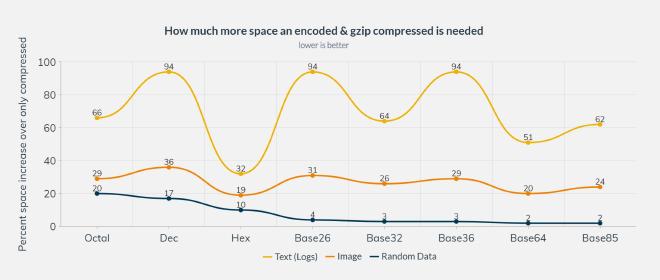
For this experiment I used gzip and the following data
- a JPEG (42.2 kB, 31.1 kB compressed)
- Android LogCat output (887.8 kB, 51.8 kB compressed)
- random data (1024 bytes, 1047 bytes compressed)
The data will be first encoded with the various schemes, and then compressed. The chart shows how much bigger it is compared to just the raw data compressed (lower is better).
Interestingly Hex fairs the best with real world data being considerably smaller than the more high-density encodings like ascii85 and base64. This is probably to the dictionary friendly smaller alphabet.
The full test suite can be found here.
Conclusion #
Don’t get overwhelmed by the sheer number of options to choose from. If you do not a have a specific requirement on the output character set or length, then in most cases it makes sense to stick to a common option like base64 and not worry too much about things like space efficiency. I also recommend checking the quantity and quality of available implementations before setting your mind on a specific encoding, because there is nothing more annoying than subtle incompatibilities.